





According to Stability AI and the DeepFloyd Multimedia Artificial Intelligence Research Lab, DeepFloyd IF is a model text to image Powerful and modern, it offers a high degree of photo realism and language understanding, capable of intelligently integrating text into images. It is available in open source on github.
DeepFloyd IF is a modular neural network based on a waterfall approach: it is built using several independent neural networks that handle specific tasks within a single architecture to produce a synergistic effect.
The DeepFloyd researchers trained it on about 1 billion pairs of images and text from LAION-5B, which was also used to train Stable Diffusion but unlike the latter, IF operates in pixel space.
DeepFloyd IF module
DeepFloyd IF consists of a frozen text encoder and three consecutive pixel streams.
The base diffusion model first converts the type text into a 64×64 image (The DeepFloyd team trained three versions of the base model, each with different parameters: IF-I 400M, IF-I 900M, and IF-I 4.3B.).
To amplify the image, two super-fine modal text models (U-Net efficiency) are applied to the output of the base model:
- The first of these models scales a 64 x 64 image to a 256 x 256 image. Again, several versions of this model are available: the IF-II 400M and the IF-II 1.2B.
- A second super-resolution scattering model is then applied to produce a vivid 1024 x 1024 image.
All stages of the model use a T5 adapter-based frozen text encoder to extract text merges, which are then fed into an optimized UNet architecture with mutual attention and attention pooling.
DeepFloyd has not yet released a third-stage IF model with a value of 700 million parameters, and the modular nature of the IF model has allowed other scaling models (such as the Upscaler Stable Diffusion x4) to be used in the third step.
The larger model with a 1024p booster requires 24GB of VRAM, while for the larger model with a 256p booster, 16GB is enough.
Translation from image to image
To modify the style, patterns, and detail of the output while preserving the essence of the source image, IF offers a snapshot-to-image translation: this requires resizing the original image to 64 pixels, adding noise via the forward stream and denoising the image with a new vector during the backstream process.
Results
Using the T5-XXL language model as a text encoder provides accurate alignment between generated prompts and images.
According to the team, DeepFloyd IF is also good at text integration: it generates consistent, clear text alongside objects with different properties, and it appears in different spatial relationships, which is a daunting task for most text transformation models. -picture.

On the one hand, it has a high degree of realism: although its architecture is similar to that of Imagen, DeepFloyd IF-4.3B outperformed the latter in tests, as did other models such as Stable Diffusion or DALL-E 2, achieving FID Zero-Shot score of 6.66 in the COCO data set, demonstrating superior text and image superimposition capabilities.
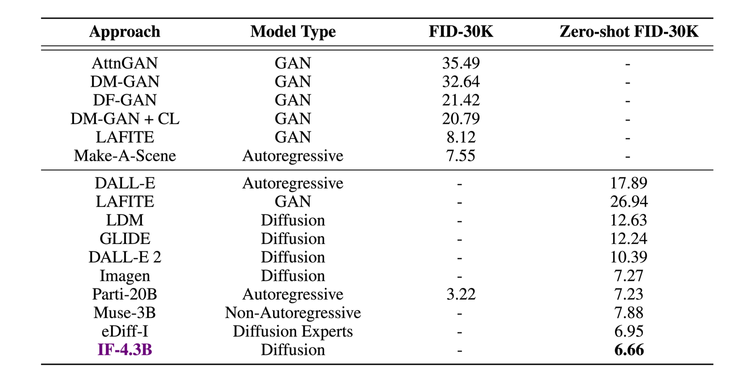 For DeepFloyd, “IF Demonstrates the Potential of Larger UNet Structures in the First Phase of Cascading Broadcast Models and Depicts a Promising Future for Text-Image Composition”. Released under a non-commercial license, it provides researchers and developers with the opportunity to explore and experiment with advanced methods of text-to-image creation. In line with its other models, Stability AI intends to release a fully open source DeepFloyd IF model at a later date.
For DeepFloyd, “IF Demonstrates the Potential of Larger UNet Structures in the First Phase of Cascading Broadcast Models and Depicts a Promising Future for Text-Image Composition”. Released under a non-commercial license, it provides researchers and developers with the opportunity to explore and experiment with advanced methods of text-to-image creation. In line with its other models, Stability AI intends to release a fully open source DeepFloyd IF model at a later date.
Article references: Stability AI, DeepFloyd
encrypted: github
Weights can be obtained by accepting license on model cards in space face hugging

“Hardcore beer fanatic. Falls down a lot. Professional coffee fan. Music ninja.”
More Stories
Starliner's first manned flight in May
Why do we feel cramps when we exercise?
We tell you everything!